Être capable de faire la différence entre un problème global et un problème local est un des principaux défis auquel nos clients font face au quotidien
Cette question n’est pas seulement importante pour le département IT d’une entreprise, c’est également important pour Microsoft.
Le nombre de tickets qui est ouvert au support de Microsoft est très important souvent du au manque de connaissance de ce qui se passe vraiment dans l’architecture même de nos clients. In fine cela a des impacts à la fois chez l’entreprises et chez Microsoft.
Il existe une manière simple pour détecter un problème sur votre tenant grâce à des sondes agissant comme un utilisateur. Voici quelques exemples concrets
Nos tests
Pour ce premier test, nous avons fait fonctionner 10 Sondes ou robots utilisateurs depuis plusieurs sites différents (Azure, Bangalore, Boston, Nice, Philadelphie) avec différentes configurations (avec ou sans proxy, connecté au siège en Europe ou non, etc.). Ce sont ceux sélectionnés dans le graphique ci-dessous.
Nous observons ensuite comment Office 365 procède pour se connecter avec les différents tenants et à travers plusieurs scénarios de configuration.
Allons voir les statistiques et tendances sur l’expérience utilisateur finale et observons les résultats.
Premier lot de résultats
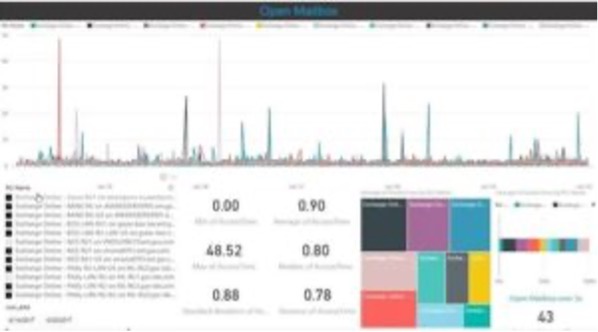
Voici les données de tous les robots-utilisateusr. L’objectif est de voir si les tendances de connexion sont cohérentes.
En haut, nous voyons une graphique linéaire qui compare la performance dans le temps de chaque robot-utilisateur.
Au niveau de l’Ouverture d’une boite email, à part quelques pics, la tendance semble normale, avec une performance optimale durant les weekends.
En bas à gauche, nous avons la liste de tous les robots-utilisateur (actifs ou non). En bas au milieu s’affiche quelques statistiques qui sont calculés pour mesurer la criticité des problèmes de connexion.
Le graphique carré en bas à droite compare le temps moyen pris par chaque robot-utilisateur pour réaliser l’action sélectionnée (ouverture de la boite email dans ce cas).
Vous verrez cette même structure du tableau de bord dans la plupart de nos tests.
En regardant les statistiques, il n’y a pas eu un seul moment où tous les robots-utilisateur ont eu un problème au même moment. Nous pouvons conclure les latences et problèmes survenus sont seulement d’ordre local et non « tenant wide »
Un autre élément important que nous avons observé est que la déviation standard a la même valeur que la valeur médiane, ce qui montre un spectre de connexions très stable et en bonne santé.
On observent ici qu’en analysant une seule action comme l’« ouverture d’une boite email », tout semble fonctionner normalement. Cependant nous constatant d’autres conclusions en observant le comportement des robots sur d’autres actions
Plongeons-nous dans ces autres actions pour voir si « l’ouverture de boite email » est une mesure suffisante ou non pour tester le niveau de service délivré.
Pourquoi est-ce nécessaire d’analyser différentes actions fonctionnelles sur les services Office 365 ?
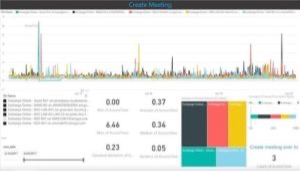
Dans cet exemple, en analysant l’action« Nouveau Rendez-vous » (create meeting) on constate des résultats un peu différent.
Nous pouvons voir quelques pics spécifiques quand chaque robot-utilisateur est impacté. Même le robot-utilisateur positionné sur Azure a été impacté par moments.
Cela conduit à des preuves solides selon lesquelles, durant ces moments précis, l’ensemble du tenant était impacté par une diminution de la performance.
Les premières actions de tests nous montrent que nous ne pouvons pas seulement nous contenter de vérifier l’ ouverture de boîte email sur un tenant car cela ne sera pas assez exhaustif pour détecter des problèmes majeures.
Les actions de chaque utilisateur ont leurs propres spécificités et performances et chacune d’entre elles peut être à l’origine de plaintes, de tickets et donc de coût de gestions
Continuons à creuser au niveau d’autres tâches.
Free-busy
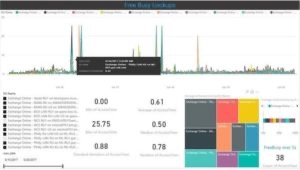
Le Free-Busy est une fonctionnalité très importante d’Outlook. Tout le monde peut l’utiliser pour planifier des réunions entre collègues tout en s’assurant qu’ils sont bien disponibles. Pour effectuer cette opération, Microsoft récupère le statut d’une autre personne à partir de son calendrier, qui peut être soit libre ou occupé, pour la période sélectionnée du meeting.
Si la recherche de disponibilité est lente, le temps de planification de la réunion avec plusieurs participants peut devenir un processus laborieux. Ici, si nous regardons ce qui s’est passé entre le 16 et le 17 juin, nous pouvons identifier les problèmes.
La question principale étant: comment savoir si c’est un problème du tenant globalement ou d’un seul site ?
Une fois encore, vous pouvez constater que plusieurs robots subissent simultanément une latence sur cette action. Et une fois encore, même sur Azure, notre robot-utilisateur a eu des problèmes pour vérifier la recherche de disponibilité.
Dans ce cas, ce fut sur un laps de temps assez court et donc pas dramatique mais cela montre des éléments réels et importants à maitriser.
Nous verrons dans d’autres articles comment d’autres configurations réseau peuvent affecter les performances de l’utilisateur final de manière positive ou négative. Mais, en regardant la corrélation avec 6 ou 7 sites différents, dont Azure qui était même en difficulté, vous aurez des éléments factuels pour ouvrir un ticket chez Microsoft
Les Solutions proposées par Altagone vous permettent d’identifier de manière efficace quand vous devez ouvrir un ticket à Microsoft ou traiter les problèmes en interne. Il est mieux d’être bien préparé avec des données factuels lorsque vous allez vous plaindre auprès de votre fournisseur cloud.
Nous proposons une solution optimale pour interagir avec Microsoft, les questions soulevées dans le cadre des tickets envoyés nécessiterons des raisons valables et seront justifiés par des faits tangibles.
Nous avons vu comme il était facile de cerner un problème de locataire et comment pouvions-nous faire émerger facilement en face de nous les problèmes.